一分鐘精華摘要:
HBM(High Bandwidth Memory,高頻寬記憶體)是專為 AI 與高效能運算誕生的新型記憶體技術。傳統記憶體(DDR)因為與處理器距離遠、車道窄,容易導致數據传输「交通大塞車」。HBM 則透過「3D 垂直堆疊」技術將記憶體晶片疊成摩天大樓,並利用先進封裝直接搬到 GPU 的「隔壁」,開啟高達數千位元的超寬車道。這種極致的傳輸速度,是釋放 AI 晶片算力的關鍵,也是 SK 海力士、三星與美光在 2026 年瘋狂爭奪的黃金戰場。
「新聞說 NVIDIA 新晶片因為 HBM 產能不足而延遲出貨,記憶體不是到處都有嗎?」
「為什麼同樣是記憶體,換上 HBM 這三個字母,身價就能翻好幾倍?」
在 上一篇我們看懂了 AI 晶片的四大家族 之後,你已經知道 GPU 就像是一萬個搬磚極快的小學生。但這時候工地出現了一個新問題:如果我們遞磚頭(數據)給小學生的速度太慢,那就算這一萬個小學生動作再快,大部分的時間也只能坐在原地發呆。
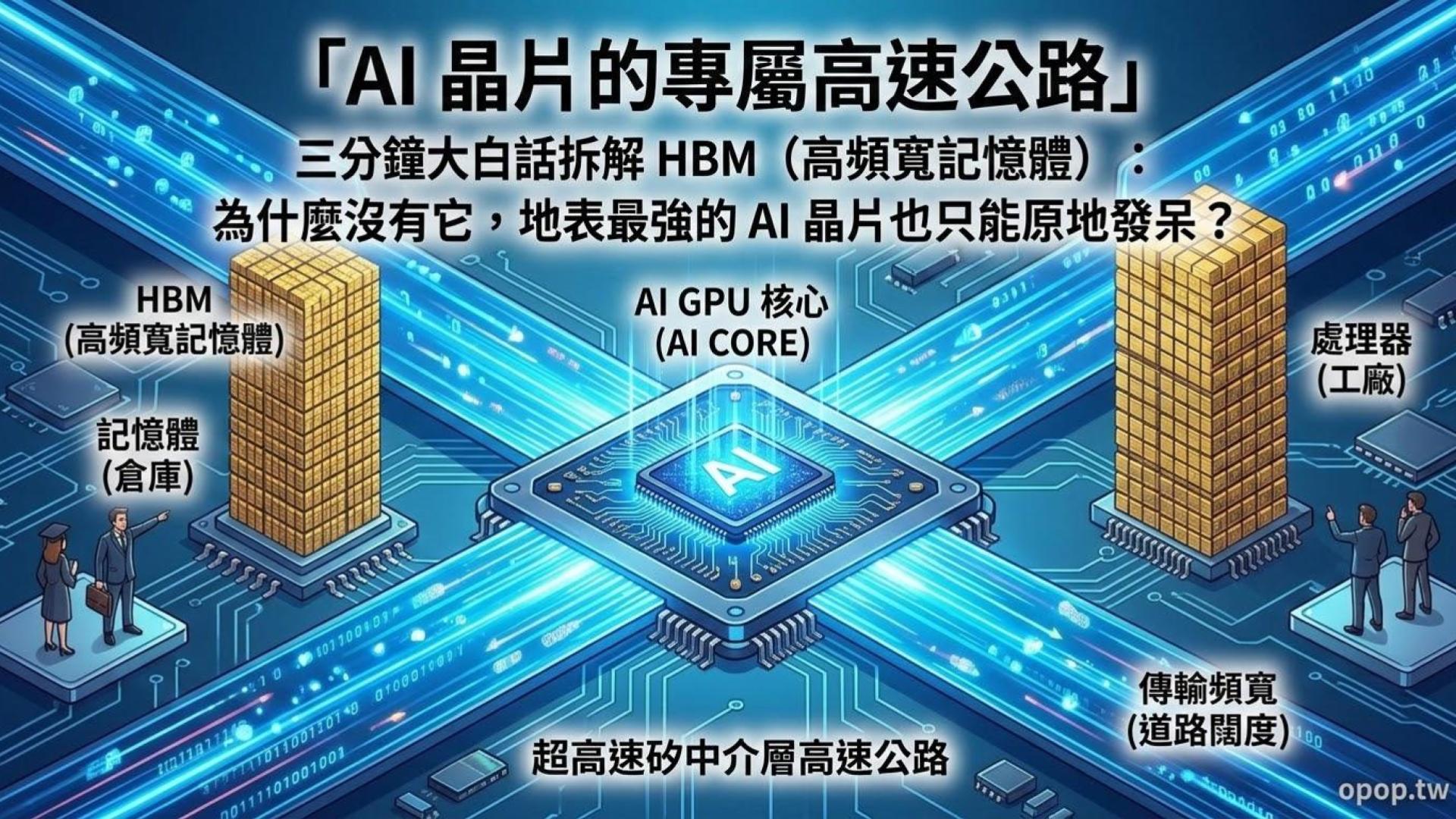
這個負責傳遞磚頭的關鍵通道,就是我們今天的主角 —— HBM(高頻寬記憶體)。
這篇文章我會用大白話告訴你,為什麼 HBM 會成為決定 AI 晶片生死存亡的「隱形心臟」,以及它背後龐大的科技商機。
1. 痛點起因:什麼是半導體的「記憶體牆(Memory Wall)」?
在傳統的電腦架構裡,大腦(CPU/GPU)和儲存數據的記憶體(DDR/顯示記憶體)是分開居住的。
大腦要算帳時,必須透過電路板上的導線,把數據從記憶體「搬」過來。
- 過去的狀況: 大腦算得不快,記憶體搬的速度也差不多,大家相安無事。
- AI 時代的災難: 現代 GPU 的算力暴增了幾百倍(小學生軍團算得極快),但傳統記憶體搬運數據的速度只提升了幾倍。
這就造成了半導體界著名的「記憶體牆」:大腦一微秒就算完了,卻要花十微秒等記憶體把下一組數據送過來。高價買來的 AI 晶片,有大半時間都在「原地待機」,這對講求效率的資料中心來說,簡直是極大的浪費。
2. HBM 的逆天解法:把記憶體蓋成摩天大樓,直接搬到隔壁
為了解決這個嚴重的塞車問題,科學家打破了傳統的思維,推出了 HBM。它的解法非常暴力且有效,主要做了兩件事:
革命一:平房變大樓(3D 堆疊技術)
傳統記憶體像是一排排的平房,佔空間又連得遠。HBM 則是利用一種叫 TSV(矽穿孔) 的技術,在記憶體晶片上打上萬個肉眼看不見的微小孔洞,然後像蓋樂高積木一樣,把 8 層或 12 層的記憶體晶片「垂直往上疊」。
這樣做不僅省空間,還能讓數據垂直傳輸,速度成倍暴增。
革命二:把大樓直接蓋在處理器的隔壁(先進封裝)
以前記憶體住在板子的另一頭,數據走的是崎嶇的小綿羊車道(32位元、64位元)。
HBM 蓋好之後,透過台積電的先進封裝技術,直接黏在 GPU 晶片的同一個底座(中介層)上。兩者之間的距離縮短到只有幾毫米,而且拉出了高達 1024 到 4096 位元的超寬「光速高速公路」。
3. 2026 實戰大數據:HBM 三巨頭的頂峰之戰
正因為 HBM 的製作難度極高,全球目前只有三家記憶體巨頭有能力玩這場遊戲。我們直接用一張表來看他們的戰況:
| 記憶體巨頭 | 市場定位與優勢 | 2026 最新動態 |
|---|---|---|
| SK 海力士 (SK Hynix) | 絕對的領頭羊、NVIDIA 核心盟友。 | 率先量產 HBM3e 與最新的 HBM4,牢牢卡位輝達旗艦供應鏈。 |
| 三星電子 (Samsung) | 技術實力雄厚、產能規模最大。 | 瘋狂衝刺產能,力求通過輝達最新晶片的嚴格認證。 |
| 美光科技 (Micron) | 美國本土巨頭、急起直追的黑馬。 | 憑藉極佳的「省電效率」切入市場,逐步瓜分市佔率。 |
我的實戰籌碼觀察:
HBM 的毛利率高達 50% 以上,遠遠超過傳統的標準 DRAM。這就是為什麼近年只要記憶體大廠宣布「HBM 順利通過認證」或是「擴產」,法人的資金就會像鯊魚聞到血一樣瘋狂湧入。對小資族來說,雖然我們不一定直接買韓股或美股,但台灣那些提供 HBM 測試設備、上游材料(如愛司摩爾 ASML 供應鏈) 的台廠,往往會跟著集體雞犬升天。
4. 💡 散戶的 AI 信心指南:看懂設備股的起漲邏輯
學會看 HBM,能幫你在面對科技股震盪時,做出更有邏輯的 資產配置與網格策略:
- 不是所有記憶體都在賺錢: 傳統電腦、手機的記憶體(DDR4/DDR5)有時會因為景氣循環而跌價;但 AI 專用的 HBM 在 2026 年依然處於極度供不應求的狀態。
- 設備與封裝才是真商機: 既然 HBM 需要垂直堆疊並黏在 GPU 隔壁,這代表台積電的 CoWoS 先進封裝 與相關的自動化檢測設備廠,訂單早就排到了幾年後。漲跌都買、定期定額這類核心概念股,才是散戶戰勝市場的長期王道。
總結:拓寬了車道,接下來要換「傳輸革命」了
HBM 成功把記憶體大樓搬到了大腦隔壁,徹底解決了數據塞車的燃眉之急。但隨著大腦算力繼續往四萬點、五萬點的台股格局飆升,晶片內部的「銅線導線」又開始面臨發熱和速度極限了。
這就逼得全球科技巨頭不得不在 2026 年聯手發動下一場革命 —— 也就是CPO(共同封裝光學)與矽光子技術。
重點筆記:
- 塞車痛點: AI 晶片算得太快,傳統記憶體搬運太慢,形成了阻礙效能的「記憶體牆」。
- 大樓結構: HBM 透過 3V 垂直堆疊(TSV)與先進封裝,把記憶體做成大樓並直接貼在 GPU 隔壁。
- 超高頻寬: 開啟了數千位元的超寬車道,是釋放 NVIDIA 頂級 AI 晶片完整實力的唯一解法。
想問問各位…
看完了 HBM 的「高速公路拓寬計畫」,當你在選擇接下來的 AI 投資標的分佈時,你對哪一個區塊最感興趣?
- A. 上游記憶體三巨頭(如美光、SK海力士),直接賺取 HBM 晶片的高毛利。
- B. 台灣先進封裝與設備鏈,畢竟 HBM 堆疊與黏合,100% 離不開台積電生態系。
- C. 我選擇直接買打包好的半導體 ETF,讓專家幫我配置,省去研究個別認證進度的麻煩。

